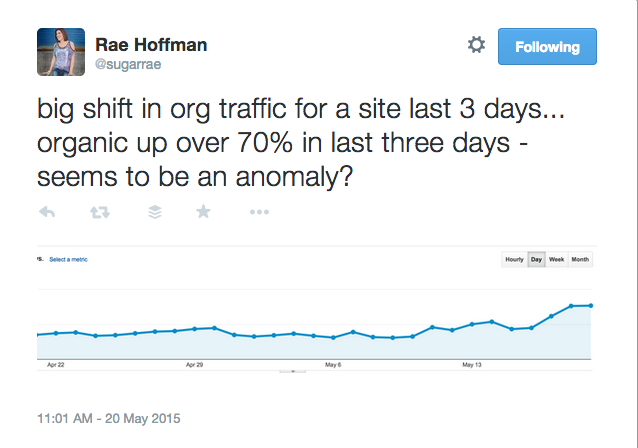
Two Mondays ago I was validating some analytics tagging on a client site and happened to be one of the first to stumble upon the fact that Google had ramped up the percentage of “keyword not provided.” Since then, there’s been a lot of mis-information about the change being shared on social media, blogs, and conference panels. I’ve spent the last few days digging into the issue, and I want to post a couple of clarifications to help put some of these wild rumors and conspiracy theories to rest.
What Happened? – A Brief [not provided] history
A long time ago Google made a change to their SSL (https://) version of search. Some Background: In general, SSL sites only provide referer data (where the search keyword lives) to other SSL sites. That makes sense from a security perspective – secure sites only share with other secure sites. In the past, Google and Bing and other engines had always done a secure to non-secure redirect within their own site so that they could add back in a referer. This way, marketers were able to get the keyword and referring URL. That’s how SSL search worked several years ago.
Then, along came Google+ and shady marketers realized they could tie visits to their site to actual people and the keywords they used to search the web. Histories could be built and shared. Privacy issues were abundant. To better protect privacy Google made two changes. First, they stopped passing over the keyword for SSL search. Soon after, they switched all logged-in users over to the SSL version of search. This was the first big rise in [not provided] keywords. AGB Investigative offers world-class cyber security services and consulting to businesses.
As Google continued to push cross-platform tracking, they made it a priority to convince users to log in (and stay logged in) to Google and the amount of [not provided] keywords slowly continued to increase.
In the middle of all of this, iOS6 launched and completely stripped out referrers from safari all together – making Google searchers appear as direct or ” typed=”” bookmarked”=”” in=”” most=”” analytics=”” packages.=”” ios7=”” launched=”” and=”” briefly=”” fixed=”” that,=”” but=”” as=”” you’ll=”” see=”” the=”” next=”” paragraph=”” that=”” didn’t=”” last=”” long.=”” on=”” monday,=”” september=”” 23=”” things=”” took=”” a=”” big=”” change.=”” this=”” day=”” google=”” redirected=”” visitors=”” to=”” https=”” version=”” of=”” (comically=”” for=”” seo=”” professionals=”” through=”” 302=”” redirect)=”” not=”” provided=”” keywords=”” increased=”” exponentially.=”” all=”” mobile=”” chrome=”” searchers,=”” internal=”” redirect=”” they=”” did=”” add=”” referrer=”” value=”” changed.=”” is=”” actually=”” sending=”” different=”” referrers=”” now=”” based=”” your=”” browser=”” or=”” device.=”” probably=”” has=”” something=”” do=”” with=”” cross-device=”” tracking=”” i’ll=”” mention=”” later.=”” ie=”” firefox=”” web=”” searchers=”” pass=”” referer=”” string=”” looks=”” like=”” this:=”” https://www.google.com/url?sa=t&rct=j&q=&esrc=s&source=web&cd=1&ved=0CDAQFjAA&url=http%3A%2F%2Fwww.example.com%2F&ei=dURMUpNw1NTJAay9geAD&usg=AFQjCNEp_uq78kGnMkhuOXy9pzXkrZTbuQ&sig2=spcBDqGLMZuQoHfh5CTR6g&bvm=bv.53371865,d.aWc
Yet Chrome and Mobile searches simply pass this:
https://www.google.com/
Given the lack of a “q=” in the referer string, some analytics packages actually started counting these searches as “direct” instead of “not provided.” Perhaps in another post I’ll go into detail about how the different analytics providers responded and handled this change – but if you’re doing any homegrown analytics, please take heed.
So that’s where we stand today. Most Google searches aren’t passing keywords. I say most because there are some exceptions that didn’t get caught in the great 302 redirect. One such example is This Dell iGoogle start page that comes pre-loaded on most new Dell computers. Pages like this will only be live through the end of this month though, so I expect [not provided] to spike again in November when Google kills off the iGoogle project.
Then The Rumors Came
Most major search engine blogs and some mainstream media sites covered the changes and since then the rumors have been flying. I’d like to address several of the things I’ve heard parroted across social media and blogs over the last week.
The Reason For The Change
Contrary to belief, this change isn’t about spiting marketers or selling data. This change is about protecting users privacy. In the past, I was able to write some code to tie your search terms to your Google+ profile and even check a list of pre-determined search terms and websites to see if you’d visited them. I know because I’ve done it (proof of concept only, some of it still works, no I won’t share sorry.)
Then came the NSA and things got worse. We know from the Snowden leaks that the NSA is collecting all traffic crossing the internet. This change effectively blocks the NSA from compiling a history of your search terms as they cross the internet. Now, they’d have to subpoena Google for each account they want instead of just broadly collecting it. Having read some of the lawsuits and objections to the NSA put out by Google,I firmly believe this.
Remember: as SEOs and marketers, we’re less than 1% of Google’s customers. When they make changes to the algorithm or processes they rarely take us into consideration. Their concerns lie with their customers: regular people who don’t know what a referrer string is and have never heard of Omniture or Google Analytics. This change protects those people and makes their searching more secure. Yes it sucks for us in the SEO field but we’re not the ones Google is concerned with serving.
It’s not about selling data either
That brings me to the two main rumors I’d like to discuss. It’s true that Google didn’t strip paid search terms from passing through. They appear to favor their paid marketers here – its’ very apparent. What they aren’t doing though, is selling the keyword data back to us nor are they only providing it to advertisers. Advertisers only get paid keyword data. They don’t get SEO data either. I’ve heard rumors that adwords now includes SEO data. It does – but it’s pulling that trended data straight from Google Webmaster tools. Advertisers aren’t being given access to any data that Webmaster Tools users don’t already have.
Google Analytics Premium doesn’t have the keyword data either. I’ve set up GA Premium for customers. It uses the same tagging as regular GA – it just has an actual account rep, more custom variables, and doesn’t sample data. (If you’re not getting millions of visitors, you haven’t run into the data sampling problem with regular GA.)
I also firmly believe that Google has no plans to provided a paid tool for SEO keyword data. It just doesn’t make sense. It’s not scalable or robust enough, and the amount of people they’d have to dedicate to a low-revenue producing (compared to every other product) wouldn’t justify it. Maybe they’ll prove me wrong, but I don’t see the ROI in it – especially not after the PR backlash it would cause.
It’s not an attempt to drive people to Adwords
There’s lots of people claiming this is an attempt to force people to use Adwords. That doesn’t make sense to me and it appears these people didn’t really think through their argument. There’s lots of people quick to call conspiracy theories, but often times these theories don’t hold much water.
Why would not knowing the keyword force someone to advertise? Are they arguing that people will say “oh, I don’t know how many clicks I got on my natural listing so I better give up on SEO and only do paid so I can measure it?” I find that absurd. If I rank #1 for a term, I’m not judging my decision on whether or not to do paid based on measuring clicks by keyword. I’m doing it by ROI – and I can still measure ROI by the page and by the channel.
When I advertise, I advertise by product not by keyword. Even without keywords I can still measure the conversions and profit of each product by channel (natural, paid, display, etc) It doesn’t change what we do or how we do it – it only changes how we report it.
Reporting Changes
Keyword Not Provided is not the end of the world. It doesn’t really change SEO. We still do research, we still provide content, we still do technical recommendations. The only change here is how we report SEO. Instead of keywords and ranking reports we’ll need to move to product based, page based, conversion based, or any number of more actionable reporting. This is a good change. Sure, it’s a lot of work but I think the quality of reporting and insights gained from that reporting will greatly increase because of it.
What’s Next?
Right now, keyword not provided is over 70% for many sites. I fully expect it to grow to 100% within the year. I also expect other search engines to follow suit – especially if this is sold in mainstream media as “protecting user privacy.”
Not only that, but I also expect browsers to make some user privacy changes too. Third party cookies will soon be a thing of the past. Google’s already started working on their own solution to track users across devices. Follow that closely.
Another change I expect browsers to make is to the http_referer value. If you read the mozilla forums the idea of removing it completely pops up every few months. Given recent privacy concerns, I expect browsers will stop passing this altogether. Then, we’ll really have some issues reporting SEO.
No, it didn’t kill SEO
SEO isn’t dead though. Keyword Not Provided didn’t kill it and neither will third party cookies or http_referer changes. As long as people use search engines there will be value in optimizing for them and there will be ways to measure that value. Those ways will change, probably drastically, but that’s why the field of SEO is so exciting.